
Before one can tell if a file is malicious or clean,

it’s important to determine the file type,

and then if the file is valid or corrupted:
If the file is indeed corrupted (aborted download…), there is no point in checking further. However, pretending to be corrupted while being valid is a way to evade detection: if the file can still run properly, it might infect a user and exploit a system, even if it may look invalid according to the official specifications.
So your reaction might be:
“Just do your work properly, and implement the official specifications”.
Sadly, it’s not that easy:
because the official specifications are typically far from enough. They only cover the general case of what should be required in theory, not all the corner cases of everything that would actually execute in reality. Official specifications are not enough.
Example
For example, the official Adobe PDF specifications say that a PDF shall start with a signature from 8 possible values (%PDF-1.0 until %PDF-1.7). This sounds easy to check and implement, right ?
Sadly, in practice it’s quite different: Adobe Reader itself just accepts %PDF-1. , or %PDF- followed by a NULL character, and at any position within 1024 bytes.
So, the official PDF reader itself doesn’t strictly follow the official PDF specifications, made by the same company, and what it actually does is not even documented anywhere. If you want to create a robust tool, then you can be sure that official specifications are not enough !
So, if the official tool does something out of bound and undocumented, nothing prevents readers to do follow different undocumented behaviors. So the same files could lead to different interpretations, and none of them is perfectly documented!
A PDF file is made of objects. PDF objects should end with the endobj keyword.
Some objects, like the content of a page, are stream objects.A stream should be closed via the endstream keyword, and then this object should end with the usual endobj keyword.
First, ‘endstream’, then ‘endobj’.
Several readers force the end of a stream of an object if the word ‘endobj’ is present before the ‘endstream’, which means you can’t print the string “this is an endobj” as is, because it will be interpreted as the end of the object, and at the same time, the end of its stream.
The consequence? After an ‘endobj’ word in a stream, some readers will stop parsing as a stream, while others will go on until ‘endstream’ is encountered.
However, parsing the root defining element of the PDF – the trailer – doesn’t explicitely require to parse an object-like structure.
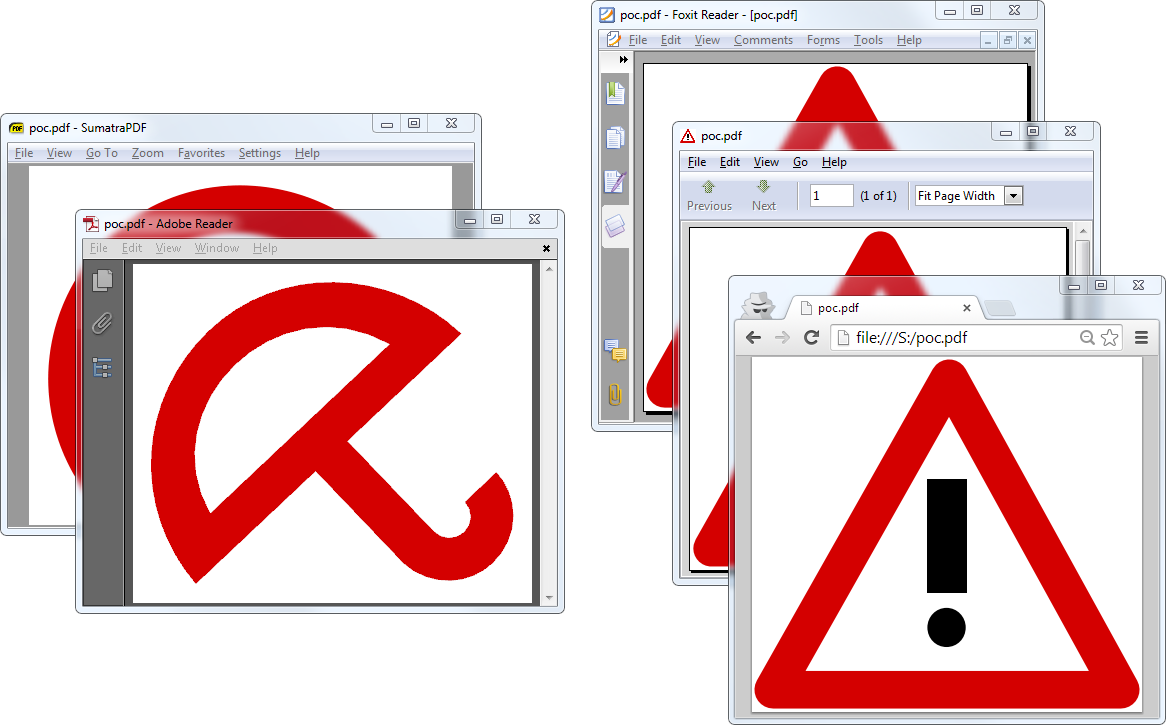
What if the trailer is defined in such an ambiguous object in a PDF (hand-made PoC, for clarity)
Some readers will parse this trailer, some won’t. So some readers will see totally different documents, with the same file:
The post Official specifications are not enough appeared first on Avira Blog.