Be honest: You’ve been waiting for the list since the New Years. I know I have. Why? It’s probably some kind of voyeurism. For some reason it’s also immensely satisfying to cringe about the horrbile passwords that people are using in their ignorance and knowing that yours is better. Hopefully.
ESET’s Trends for 2016: (In)Security Everywhere report includes a review of the most important events of last year and outlines trends in cybercriminal activity and cyberthreats for 2016.
First a brief history of Diffie-Hellman for those not familiar with it
The short version of Diffie-Hellman is that two parties (Alice and Bob) want to share a secret so they can encrypt their communications and talk securely without an eavesdropper (Eve) listening in. So Alice and Bob first share a public prime number and modulus (which Eve can see). Alice and Bob then each choose a large random number (referred to as their private key) and apply some modular arithmetic using the shared prime and modulus. If everything goes as planned Alice sends her answer to Bob, and Bob sends his answer to Alice. They each take the number sent by the other party, and using modular arithmetic, and their respective private keys are able to derive a number that will be the same for both of them, known as the shared secret. Even if Eve listens in she cannot easily derive the shared secret.
However if Eve has sufficiently advanced cryptographic experts, and sufficient computing power it is conceivable that she can derive the private keys for exchanges when a sufficiently small modulus is used. Most keys, today, are in the range of 1024 bit or larger meaning that the modulus is at least several hundred digits long.
Essentially if Alice and Bob agree to a poorly chosen modulus number then Eve will have a much easier time deriving the secret keys and listening in on their conversation. Poor examples of modulus numbers include numbers that are not actually prime, and modulus numbers that aren’t sufficiently large (e.g. a 1024 bit modulus provides vastly less protection than a 2048 bit modulus).
Why you need a good prime for your modulus
A prime number is needed for your modulus. For this example we’ll use 23. Is 23 prime? 23 is small enough that you can easily walk through all the possible factors (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12), divide 23 by them and see if there is a remainder. But much larger prime numbers, such as ones that are in the mid to high hundreds of digits long, are essentially impossible to factor unless you have a lot of computational resources, and some really efficient ways to try and factor prime numbers. Fortunately there is a simple solution to this, just use an even larger prime number, such as a 2048, 4096 or even 16384 bit prime number. But when picking such a number how can you be sure it’s a prime and not easily factored? Ignoring the obvious give-aways (like all numbers ending in 0, 2, 4, 5, 6 and 8) there are several clever mathematical algorithms for testing the primality of numbers and for generating prime numbers.
Miller-Rabin, Shawe-Taylor and FIPS 186-4
The Miller-Rabin primality test was first proposed in 1976, and the Shawe-Taylor strong prime generation was first proposed in 1986. One thing that is important to remember, is that back when these algorithms were made public the amount of computing power available to generate/factorize prime numbers was much smaller than is now available. The Miller-Rabin test is a probabilistic primality test, you cannot conclusively prove a number is prime, but by running the Miller-Rabin test multiple times with different parameters you can be reasonably certain that the number in question is probably prime and with enough tests your confidence can approach almost 100%. Shawe-Taylor is also probabilistic, you’re not 100% guaranteed to get a good prime, but the chances of something going wrong and getting a non-prime number are very small.
FIPS 186-4 covers the math and usage of both Miller-Rabin and Shawe-Taylor, and gives specific information on how to use them securely (e.g. how many rounds of Miller-Rabin you’ll need to use, etc.). The main difference between Rabin-Miller and Shawe-Taylor is that Shawe-Taylor generates something that is probably a prime, whereas with Miller-Rabin you generate a number that might be prime, and then test it. As such you may immediately generate a good number, or it may take several tries. In testing on a 3Ghz CPU, using a single core it took me between less than a second and over 10 minutes to generate a 2048 bit prime using the Miller-Rabin method.
Generating primes in advance
The easiest way to deal with the time and computing resources needed to generate primes is to generate them in advance. Also because they are shared publicly during the exchange you can even distribute them in advance, which is what has happened for example with OpenSSL. Unfortunately many of the primes currently in use were generated a long time ago when the attacks available were not as well understood, and thus are not very large. Additionally, there are relatively few primes in use and it appears that there may be a literal handful of primes in wide use (especially the default ones in OpenSSL and OpenSSH for example). There is now public research to indicate that at least one large organization may have successfully attacked several of these high value prime numbers, and as computational power increases this becomes more and more likely.
To generate Diffie-Hellman primes in advance is easy, for example with OpenSSL:
openssl dhparam [bit size] -text > filename
so to generate a 2048 bit prime:
openssl dhparam 2048 -text
Or for example with OpenSSH you first generate a list of candidate primes and then test them:
Please note that OpenSSH uses a list of multiple primes so generation can take some time, especially with larger key sizes.
Defending – larger primes
The best defense against someone factoring your primes is to use really large primes. In theory every time you add a single bit to the prime you are increasing the workload significantly (assuming no major advances in math/quantum computing that we don’t know about that make factorization much easier). As such moving from a 1024 bit to 2048 bit prime is a huge improvement, and moving to something like a 4096 bit prime should be safe for a decade or more (or maybe not, I could be wrong). So why don’t we simply use very large primes? CPU power and battery power are still finite resources, and very large primes take much more computational power to use, so much so that very large primes like 16384 bit primes become impractical to use, introducing noticeable delays in connections. The best thing we can do here is set a minimum prime size such as 2048 bits now, and hopefully move to 4096 bit primes within the next few years.
Defending – diversity of primes
But what happens if you cannot use larger primes? The next best thing is to use custom generated prime numbers, this means that an attacker will have to factor your specific prime(s), increasing their workload. Please note that even if you can use large primes, prime diversity is still a good idea, but prime diversity increases the amount of work for an attacker at a much slower rate than using larger prime does. The following apps and locations contain primes you may want to replace:
OpenSSH: /etc/ssh/moduli
Apache with mod_ssl: “SSLOpenSSLCondCmd DHParameters [filename]” or append the DH param to the SSLCertificateFile
Some excellent articles on securing a variety of other services and clients are:
I think the best plan for dealing with this in the short term is deploying larger primes (2048 bits minimum, ideally 4096 bits) right now wherever possible. For systems that cannot have larger primes (e.g. some are limited to 768, 2013 bits or other related small sizes) we should ensure that default primes are not used and instead custom primes are used, ideally for limited periods of time, replacing the primes as often as possible (which is easier since they are small and quick to generate).
In the medium term we need to ensure as many systems as possible can handle larger prime sizes, and we need to make default primes much larger, or at least provide easy mechanisms (such as firstboot scripts) to replace them.
Longer term we need to understand the size of primes needed to avoid decryption due to advances in math and quantum computing. We also need to ensure software has manageable entry points for these primes so that they can easily be replaced and rotated as needed.
Why not huge primes?
Why not simply use really large primes? Because computation is expensive, battery life matters more than ever and latency will become problems that users will not tolerate. Additionally the computation time and effort needed to find huge primes (say 16k) is difficult at best for many users and not possible for many (anyone using a system on a chip for example).
Why not test all the primes?
Why not test the DH params passed by the remote end, and refuse the connection if the primes used are too small? There is at least one program (wvstreams [wvstreams]) that tests the DH params passed to it, however it does not check for a minimum size, it simply tests the DH params for correctness. The problem with this is twofold, one there would be a significant performance impact (adding time to each connection) and two, most protocols and programs don’t really support error messages from the remote end related to the DH params, so apart from dropping the connection there is not a lot you can do.
Summary
As bad as things sound there is some good news. Fixing this issue is pretty trivial, and mostly requires some simple operational changes such as using moderately sized DH Parameters (e.g. 2048 bits now, 4096 within a few years). The second main fix for this issue is to ensure any software in use that handles DH Parameters can handle larger key sizes, if this is not possible then you will need to place a proxy in front that can handle proper key sizes (so all your old Java apps will need proxies). This also has the benefit of decoupling client-server encryption from old software which will allow you to solve future problems more easily as well.
This is a reprint of The elusive “P” which appeared in the January 2016 issue of Indian Management.
There is no such thing as a free lunch, truly.
As we increasingly traverse the virtual realm, we are putting at stake a crucial aspect—our much-treasured privacy.
There is not a lot of privacy on the Internet today. Every place you go – websites, social networks, apps – all know your IP address and where you are located, which they can correlate with your demographics, age, gender, and the websites that you visit. Social networks can even tell advertisers what your political leanings are and which religion you practice, and the Internet knows which books you read, which cosmetics you use, and whether or not you are pregnant, getting married or divorced. At the end of the day, search engine companies and Internet Service Providers know everything about you. With the up-rise of the Internet of Things, Internet-connected devices can dig even deeper into our lives. Our cars remember when we drove where, how fast we went, and what music we were listening to, while our smart watch can tell us more about our health than our doctors can. Privacy is a thing of the past.
A trade-off between convenience and privacy
In our day-to-day usage of the Internet, each of us are either making a conscious or unconscious trade-off between convenience and privacy.
One example of this can be seen in Gmail, the hugely popular email service used by nearly one billion people around the world. Most people will, but others might not recognize that they receive advertisements which are somewhat related to the subject of their emails. This is due to the fact that the subjects of a user’s emails are sent to various advertising engines to come up with relevant content to serve back to the Gmail user. For someone who sent an email with ‘vacation’ in the subject line, this may result in the user receiving ads with flight offers during the following days.
As a consumer searching for different things on the Internet, you are likely making the connection that advertisements that you see are based on the searches you have recently made. This is the result of targeted advertisements, which can simultaneously provide true value and can also cause problems or be embarrassing. For example, if a family shares one computer, certain family members may not want their parents or children knowing about their search history. This becomes difficult to avoid with targeted ads, since the ads displayed are related to search items that were originally intended to be confidential.
Taking this a step further, we also need to start thinking about the advancement of our smart devices. One big enabler of privacy violations is geographic tracking embedded in everyone’s devices — from our smartphones to our cars. As geotracking becomes an everyday feature in cars, people can effortlessly follow their spouse or child while they are driving, keeping track of their speed, location and driving habits. While this could potentially encourage safe driving, it could also have negative effects on those who don’t want to be surveilled. What’s more, the data collected by a car could be sold to insurance companies that will refuse payment in the case that an accident was caused by speeding.
For the most part, people may understand the risks that come along with the development of smart devices. However, when feeding companies with mass amounts of data collected by these devices, users continue to make a conscious trade-off that results in the loss of their personal privacy.
Free software and the lure of fast click-through agreements
One of the reasons why people so easily and willingly give up their privacy is that most of the software they download comes with no price tag attached to it. Back in the 90s, software was sold in stores and was fairly expensive for the average consumer. Now that the majority of software is downloaded online and is distributed largely free of charge, the products come with a price tag of a different kind — the infringement on consumers’ privacy and security. This issue is heightened by the fact that many people don’t take the time to read through their software’s click-through agreements.
The real question is this: What does a user receive in exchange for giving up their privacy? Additionally, are they willing to lose the convenience that software and apps provide if they want to keep their privacy intact?
Certain services of trusted companies can serve very useful purposes, such as free email services, search, text messaging, social networking, health monitoring, or child safety; and targeted advertising by social networks, search engines and other web services is not seen as risky. The more an app or web service knows about you, such as your location, your interests, your contacts, the better they can target you. Some people prefer seeing targeted ads, as the ads displayed become increasingly relevant for them, while others find targeted advertising to be, to a certain extent, an invasion of privacy.
The only way to completely prevent being spied on in today’s day and age would be to not use the Internet nor smart devices and free services that access sensitive data in order to target ads.
There are, however, tools in the market, like browser-add-ons that provide consumers with information on web interactions with social media sites, advertising networks that share data, and the analytics used to improve a website. Clever technology can identify these from either cookies or programming code that is embedded in the website. There are also apps for mobile users helping them understand which data apps can access and which ad networks they serve.
A joint effort needed between industry and politics
Although there are solutions available, it cannot be solely the consumer’s burden to determine how to navigate the trade-off between privacy and convenience. It’s not possible for users to stay 100% informed about what happens to their data, as most companies simply don’t communicate these things to their customer base. To combat this issue, companies should focus on increasing their transparency, making their privacy agreements easy to the average user to understand, and putting significant effort into educating their customers. Politicians will also need to determine just how far companies can legally go with the collection and distribution of user data.
People’s choice of passwords continues to be a huge security risk, according to new research. SplashData’s annual Worst Passwords List finds ‘123456’ and ‘password’ continue to be the most common choice.
It’s possibly one of the oldest and least plausible scams out there, but the infamous Nigerian scam is still a popular method used by cybercriminals as they look to that advantage of would-be victims online.
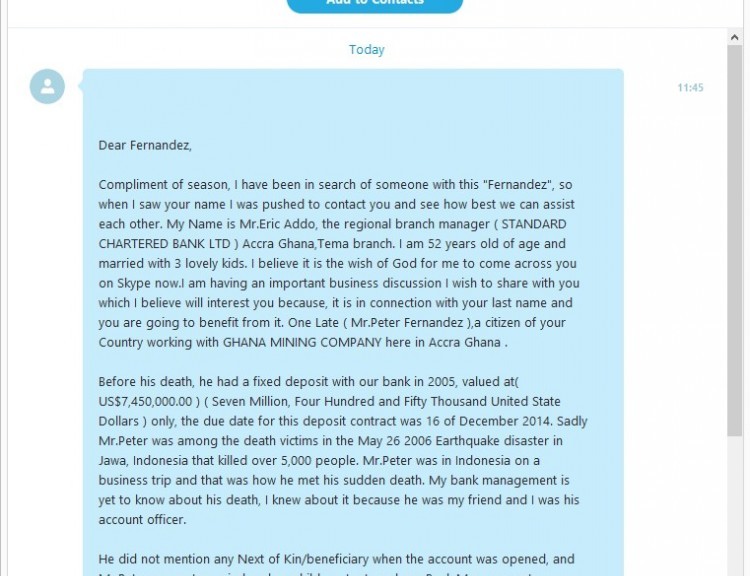
What was once an email-based scam has since taken to Skype, where one of our colleagues recently received the following (and strangely worded) message via the communication service:
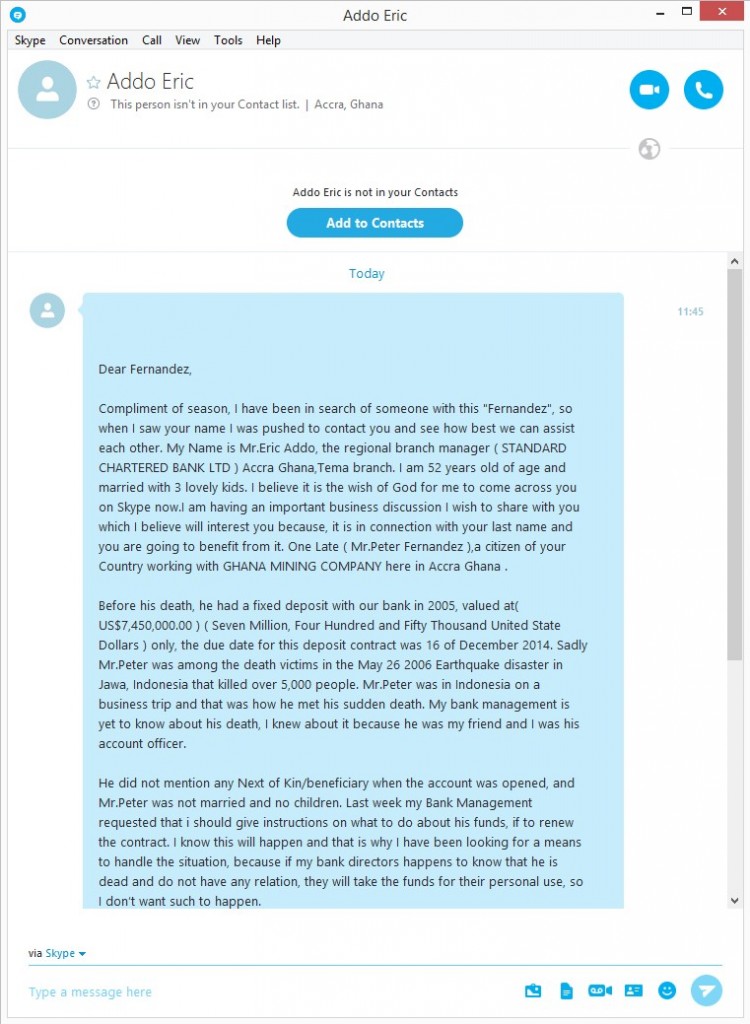
As you can see, they tell you that a victim of an Indonesian earthquake has died, leaving behind a princely sum of $7.5 million in a bank account. Luckily for our colleague, his surname, Fernández, is the same as the victim’s. This is a sufficient a link as needed for the earthquake victim’s friend to get in touch with his generous offer.
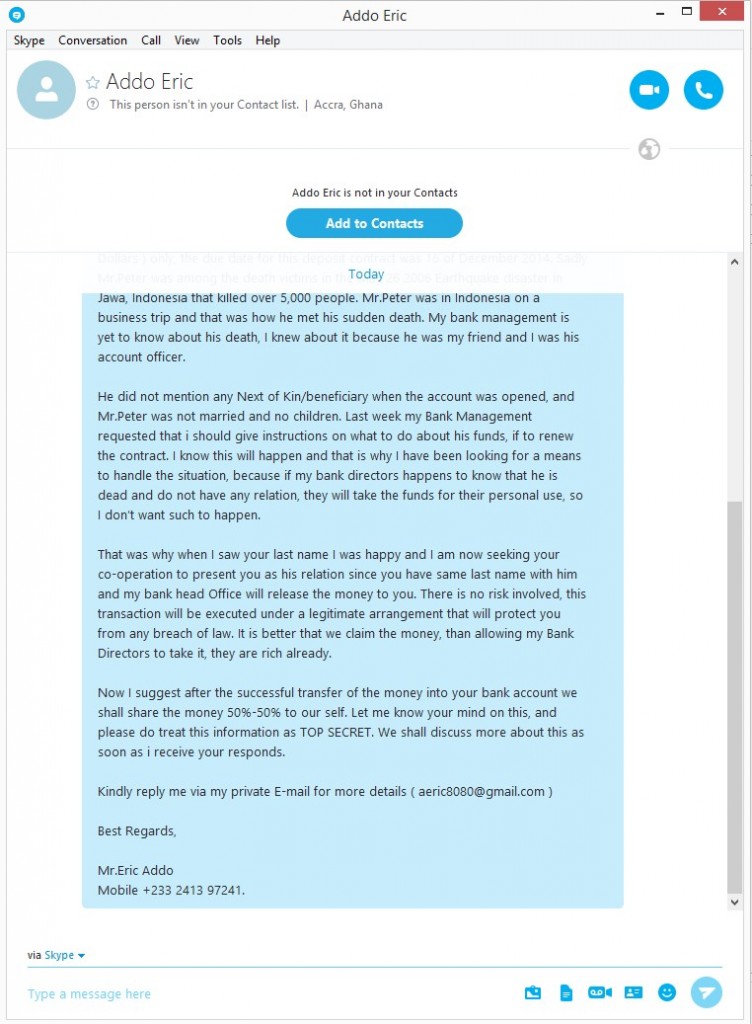
What the scammer proposes is that the sum of money stored in the bank account be shared equally between both parties, although the operation must be done under utmost secrecy and without anyone else knowing about it. In order or the deal to be carried out and for more details on how the transfer will be done, our Nigerian friend needs our colleague to get in touch with him.
It’s blatantly obvious that there is no money to be exchanged in all of this, and that there was never any earthquake victim to begin with. These scammers simply contact us with the hope of getting our private information and to try access our bank accounts.
So there you have it – never give out your personal information online and never carry out banking transactions that are related to prizes, inheritances, or lotteries.
The United States has freed 4 Iranian nationals (including one Hacker) and reduced the sentences of 3 others in exchange for the release of 5 Americans formerly held by Iran as part of a prisoner swap or Prisoner Exchange Program.
The Iranian citizens released from the United States custody through a side deal to the Iran nuclear agreement.
APPLE-SA-2016-01-19-1 iOS 9.2.1
iOS 9.2.1 is now available and addresses the following:
Disk Images
Available for: iPhone 4s and later,
iPod touch (5th generation) and later, iPad 2 and later
Impact: A local user may be able to execute arbitrary code with
kernel privileges [...]
APPLE-SA-2016-01-19-2 OS X El Capitan 10.11.3 and Security Update
2016-001
OS X El Capitan 10.11.3 and Security Update 2016-001 is now available
and addresses the following:
AppleGraphicsPowerManagement
Available for: OS X El Capitan v10.11 to v10.11. [...]